
AI概念
AI模型
AI模型是用于处理和生成信息的算法,通常模拟人类认知功能。通过从大规模数据中学习模式与洞察,这些模型能够进行预测、生成文本、图像或其他输出,从而推动各行业的应用发展。
模型类型
AI模型种类繁多,各适配特定应用场景。尽管ChatGPT及其生成式AI能力因文本输入输出而广受关注,但许多模型和公司提供了多样化的输入输出形式。在ChatGPT之前,文本生成图像模型(如Midjourney和Stable Diffusion)已引发广泛兴趣。
以下表格根据输入输出类型对模型分 
Spring AI支持的模型
Spring AI目前支持处理语言、图像和音频 输入输出的模型。表格最后一行(文本输入输出数值)通常称为文本嵌入(Embedding) ,表示AI模型内部的数据结构。Spring AI已支持嵌入技术以实现更高级的用例。
预训练模型的优势
以GPT(Chat Generative Pre-trained Transformer)为代表的模型因其预训练(Pre-trained)特性而脱颖而出。预训练使AI成为通用开发工具,开发者无需深厚的机器学习或模型训练背景即可使用。
提示(Prompts)
提示是指导AI模型生成特定输出的语言输入基础 。对于熟悉ChatGPT的用户,提示可能看似只是输入到对话框中的文本,但其内涵远不止于此。在许多AI模型中,提示文本并非简单的字符串。
以ChatGPT的API为例,提示包含多个文本输入,每个输入被赋予不同角色:
- 系统角色(System Role) :定义模型的行为和交互上下文(如“你是一个友好的助手”)。
- 用户角色(User Role) :通常为用户的输入内容。
设计有效提示既是艺术也是科学。与SQL等结构化查询语言不同,与AI模型的交互更接近人与人的对话 ,需通过自然语言引导模型生成期望结果。
- 重要性:提示工程已成为独立学科,涌现了大量提升提示效果的技术。精心设计的提示可显著优化输出质量。
- 实践与研究:提示共享成为社区实践,学术界也在积极研究这一领域。例如,研究发现以“深呼吸并逐步解决问题”开头的提示效果显著,凸显了语言表达的关键性。
提示模板(Prompt Templates)
有效提示的创建需结合上下文定义 和动态替换用户输入 。Spring AI通过开源库StringTemplate 实现模板化管理。
示例模板 :
讲一个{形容词}的关于{内容}的笑话。
在Spring AI中,提示模板类似Spring MVC架构中的“视图”:
- 提供java.util.Map对象填充占位符(如形容词和内容)。
- 渲染后的字符串作为提示内容传递给AI模型。
提示的数据格式已从简单的字符串发展为多消息结构 ,每条消息代表不同角色(如系统、用户、工具调用)。这种结构化设计增强了模型对复杂交互的处理能力。
嵌入(Embeddings)
嵌入是文本、图像或视频的数值表示,能够捕捉输入数据之间的关联。 其工作原理是将文本、图像和视频转换为浮点数数组(即向量),这些向量旨在捕获原始数据的语义。向量的长度称为维度 ,例如一个嵌入向量可能是768维或1536维。

通过计算两个文本向量表示之间的数值距离(如余弦相似度或欧氏距离),应用程序可判断生成这些向量的对象之间的相似性。
Java开发者视角
作为探索AI的Java开发者,无需深入理解嵌入背后的复杂数学理论或具体实现。仅需了解其在AI系统中的作用与功能 ,尤其在集成AI功能时。
实际应用与语义空间
嵌入在检索增强生成(RAG)等场景中至关重要。它们将数据表示为 语义空间 中的点,类似于欧几里得几何的2D空间,但维度更高:
- 语义空间特性 :
- 点之间的接近性反映语义相似性(如相似主题的句子在空间中位置更近)。
- 例如,在文本分类中,嵌入可将“猫”和“狗”映射到相邻区域,而“汽车”则可能位于更远的位置。
- 应用场景 :
- 文本分类 :通过向量聚类识别相似内容。
- 语义搜索 :返回与查询意图最接近的结果。
- 产品推荐 :基于用户行为嵌入推荐关联商品。
令牌(Tokens)
令牌是AI模型处理和生成文本的基本单元。
- 输入阶段 :模型将单词转换为令牌。
- 输出阶段 :令牌被转换回单词。 在英语中,一个令牌约等于3/4个单词。例如,莎士比亚全集约90万单词,对约120万个令牌。

令牌与成本
在托管AI模型中,令牌数量直接决定费用 。输入和输出的令牌总数均会计入成本。
令牌限制与上下文窗口
模型对单次API调用处理的令牌数量设有上限,称为上下文窗口 。超出限制的文本将被截断。
示例 :
- ChatGPT-3:4K令牌
- GPT-4:8K、16K、32K选项
- Anthropic的Claude:100K令牌
- Meta最新研究模型:1M令牌
处理长文本的策略
若需处理长文本(如莎士比亚全集),需通过分块(chunking)等工程策略将数据分割为符合模型上下文窗口的片段。Spring AI项目提供了相关工具支持此任务。
结构化输出(Structured Output)
传统上,AI模型的输出以java.lang.String形式返回,即使请求JSON格式的响应也是如此。尽管输出可能是有效的JSON,但它本质上仍是一个字符串,而非结构化的数据结构。此外,通过提示词请求“JSON格式”并不能保证100%的准确性。
这一复杂性催生了一个专门领域:通过精心设计的提示词生成目标输出,并将原始字符串转换为可集成到应用程序中的结构化数据 。
结构化输出转换器架构
结构化输出转换依赖精心设计的提示词 ,通常需要多次与模型交互以实现期望的格式。例如:
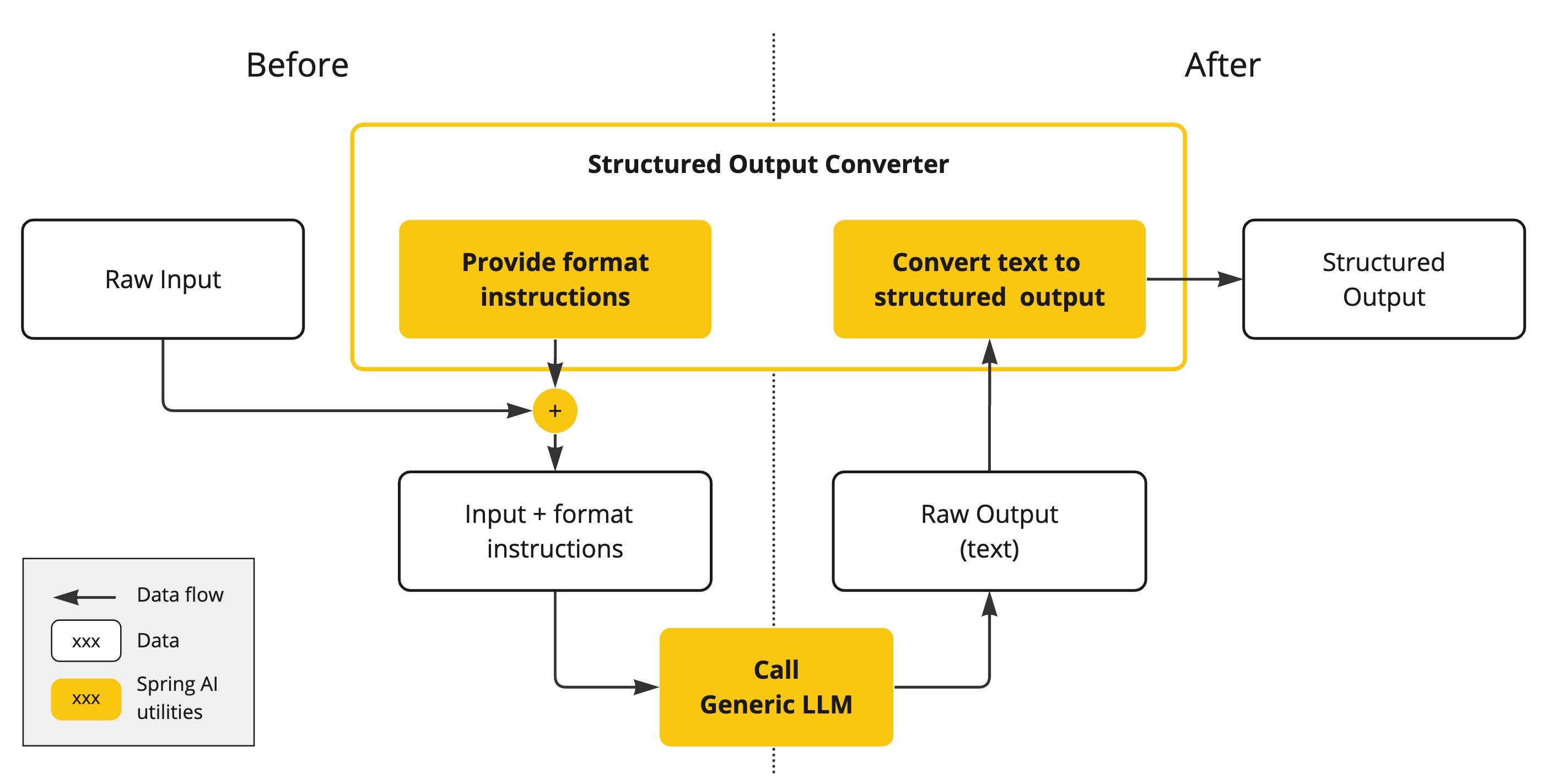
- 转换器会将预定义的输出格式(如JSON Schema)附加到提示词中,引导模型生成结构化结果。
- 若模型未能按预期输出,可能需要通过多轮迭代调整提示词或采用约束解码(Constrained Decoding)技术。
核心挑战与解决方案
- 挑战 :模型可能忽略格式指令或生成不合规的结构。
- 解决方案 :
- 使用输出解析器 (如Spring AI的StructuredOutputConverter)将原始响应转换为Java对象。
- 通过提示工程 明确约束条件(如JSON Schema),提升生成结果的可靠性。
将数据与API引入AI模型
如何让AI模型掌握其未受训的数据? 需注意,GPT 3.5/4.0的数据集更新截止到2021年9月。因此,模型对涉及该日期后的信息会回答“未知”。有趣的是,该数据集规模约为650GB。
三种定制模型的技术
- 微调(Fine Tuning) 传统机器学习方法,通过调整模型内部权重适配特定数据。但对大型模型(如GPT)而言,此过程对机器学习专家极具挑战且资源消耗巨大,部分模型甚至不开放此功能。
- 提示填充(Prompt Stuffing) 更实用的替代方案,将外部数据嵌入到模型的输入提示(Prompt)中。由于模型存在上下文窗口限制,需通过技术(如分块)在窗口内呈现关键数据。此方法俗称“填塞提示”,Spring AI库通过**检索增强生成(RAG)**简化其实施。
- 工具调用(Tool Calling) 通过注册自定义工具(如API服务),将大语言模型与外部系统连接。Spring AI大幅减少了支持工具调用所需的代码量。 核心机制与挑战
检索增强生成(Retrieval Augmented Generation, RAG)
检索增强生成(RAG) 是一种新兴技术,旨在解决将相关数据整合到提示中以提升AI模型响应准确性的挑战。
RAG的核心流程
- ETL(提取、转换、加载)管道
- 批量处理模式 :从原始文档中读取非结构化数据,经过转换后存入向量数据库。
- 关键作用 :向量数据库用于RAG的检索阶段,能够高效匹配相似内容。
- 文档分割的关键步骤
- 语义边界保留 : 避免在段落、表格或代码方法中间分割文档,确保内容完整性。
- 分块大小控制 : 每个分块的大小需控制在模型上下文窗口的较小比例内(如10-20%的令牌限制)。
用户输入处理阶段 当用户提问时,RAG会执行以下操作:
- 从向量数据库中检索与问题相关的文档片段。
- 将问题与检索到的文档片段共同注入提示(Prompt),发送给AI模型生成响应。
Spring AI中的RAG实现

- ETL管道 : 详细说明如何从数据源提取数据、转换为优化格式,并存储到向量数据库,确保高效检索。
- ChatClient与RAG : 通过 QuestionAnswerAdvisor 实现RAG能力,动态检索外部数据并增强生成结果。
工具调用(Tool Calling)
大型语言模型(LLMs)在训练后参数被冻结,导致其知识无法更新,且无法直接访问或修改外部数据。 工具调用机制 通过以下方式解决这些问题:
- 允许将自定义服务注册为工具,连接LLMs到外部系统的API。
- 为LLMs提供实时数据访问能力,并代其执行数据处理操作。
Spring AI大幅简化了工具调用的代码实现:
- 通过@Tool注解标记工具方法,并在提示选项中声明工具即可供模型使用。
- 支持在单个提示中定义并引用多个工具。

工具调用的核心流程
- 工具定义 :在聊天请求中包含工具定义(名称、描述、输入参数模式)。
- 模型决策 :模型根据需求选择调用工具,并返回工具名称及符合模式的输入参数。
- 应用执行 :应用通过工具名称识别并执行对应操作,传入参数。
- 结果处理 :应用将工具调用结果返回给模型。
- 最终响应 :模型结合工具结果生成最终回答。